
觉晓法考安卓版

- 文件大小:136.24MB
- 界面语言:简体中文
- 文件类型:Android
- 授权方式:5G系统之家
- 软件类型:装机软件
- 发布时间:2024-10-10
- 运行环境:5G系统之家
- 下载次数:540
- 软件等级:
- 安全检测: 360安全卫士 360杀毒 电脑管家
系统简介
Windows系统的内部确实使用了Unicode编码。Unicode是一种国际标准,用于在不同语言、字符集和平台之间统一字符的表示。Windows操作系统自Windows NT 4.0开始,已经全面采用Unicode作为其内部字符编码,这保证了它能够更好地支持多语言环境和国际化应用。
具体来说,Windows内部使用的是UTF16编码,这是Unicode标准中的一种编码方式,能够表示所有的Unicode字符。与UTF8不同,UTF16使用固定大小的码元(通常是16位,但也可以扩展到32位),这意味着它能够更直接地处理字符的编码和解码,但同时也可能占用更多的存储空间。
Windows系统的许多API都设计为使用Unicode字符串,这有助于开发者在创建软件时,不需要担心字符编码问题,从而能够更容易地支持多种语言。例如,Windows API中的`wchar_t`类型就是专门用来处理宽字符(即Unicode字符)的。
在Windows系统的文件系统中,文件名和路径也可以使用Unicode编码,这允许文件名包含多种语言的字符。
总之,Windows系统内部的Unicode支持是其国际化能力的一个重要组成部分,使得它能够在全球范围内被广泛使用。
Windows系统内部Unicode编码解析
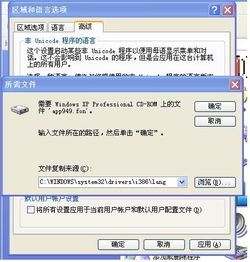
随着全球信息化的发展,Unicode编码已经成为国际通用的字符编码标准。Windows系统作为全球广泛使用的操作系统之一,其内部对Unicode编码的支持至关重要。本文将深入解析Windows系统内部的Unicode编码机制,帮助读者更好地理解其工作原理。
Unicode是一种全球统一的字符编码标准,旨在统一世界上所有的字符编码。它包含了世界上所有语言的字符,以及数学符号、技术符号等。Unicode编码采用16位或32位表示一个字符,其中16位编码称为UTF-16,32位编码称为UTF-32。
在Windows系统中,Unicode编码主要有以下几种格式:
UCS-2:双字节定长编码,具有大端与小端的区别。
UTF-16:双字节变长编码,兼容UCS-2。
UTF-32:四字节变长编码。
UTF-8:单字节变长编码,兼容ASCII。
Windows系统内部对Unicode编码的实现主要依赖于以下几个组件:
字符集:Windows系统支持多种字符集,包括ANSI、OEM和Unicode等。
编码转换:Windows系统提供了丰富的编码转换函数,如MultiByteToWideChar和WideCharToMultiByte等,用于在不同编码格式之间进行转换。
字体:Windows系统内置了多种字体,支持显示各种Unicode字符。
API函数:Windows API函数支持Unicode编码,如GetWindowTextW、MessageBoxW等。
Unicode编码在Windows系统中的应用非常广泛,以下列举几个典型应用场景:
多语言支持:Windows系统支持多种语言,用户可以根据需要切换语言环境,实现多语言输入和显示。
国际化应用:许多国际化的应用程序都采用Unicode编码,以支持全球用户的使用。
网络通信:在网络通信过程中,Unicode编码可以确保字符信息在不同平台和设备之间正确传输。
文件存储:Unicode编码可以存储各种语言的文本文件,提高文件的可移植性和兼容性。
尽管Unicode编码在Windows系统中得到了广泛应用,但仍面临一些挑战:
字体支持:并非所有字体都支持Unicode编码,特别是扩展区的字符。
编码转换:在不同编码格式之间进行转换时,可能会出现乱码问题。
性能问题:Unicode编码通常比单字节编码占用更多空间,可能会影响系统性能。
Windows系统内部对Unicode编码的支持是其国际化、多语言和兼容性等方面的关键因素。通过深入了解Unicode编码的原理和应用,我们可以更好地利用Windows系统,实现全球范围内的信息交流。



常见问题
- 2025-03-05 梦溪画坊中文版
- 2025-03-05 windows11镜像
- 2025-03-05 暖雪手游修改器
- 2025-03-05 天天动漫免费
装机软件下载排行

其他人正在下载
系统教程排行
主题下载
-
魔笛MAGI 摩尔迦娜XP主题+Win7主题
-

轻音少女 秋山澪XP主题+Win7主题
-

海贼王 乌索普XP主题+Win7主题
-

学园默示录 毒岛冴子XP主题+Win7主题+Win8主题