
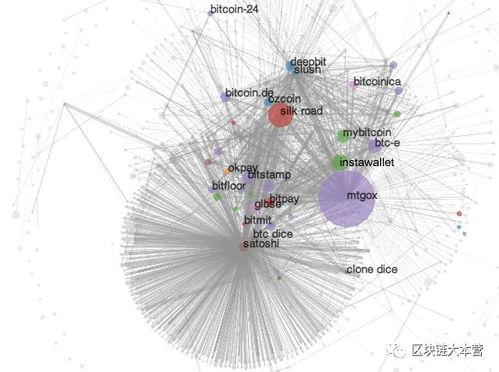
比特币聚类
- 文件大小:
- 界面语言:简体中文
- 文件类型:
- 授权方式:5G系统之家
- 软件类型:装机软件
- 发布时间:2025-01-16
- 运行环境:5G系统之家
- 下载次数:315
- 软件等级:
- 安全检测: 360安全卫士 360杀毒 电脑管家
系统简介
亲爱的读者们,你是否曾想过,在浩瀚的数据海洋中,如何找到那些隐藏的宝藏呢?其实,答案就在我们身边——那就是聚类!想象你手中握着一张张看似杂乱无章的数据卡片,而聚类就像是一位魔法师,能将这些卡片巧妙地分类整理,让你一眼就能找到你想要的“宝藏”。今天,就让我们一起走进聚类的奇妙世界,探索它的奥秘吧!
一、聚类的魔法:让数据井然有序
聚类,顾名思义,就是将相似的数据点聚集在一起,形成一个个“簇”。这个过程就像是将散落在地上的珍珠串成项链,让它们变得更有价值。那么,聚类有哪些神奇之处呢?
1. 发现隐藏模式:通过聚类,我们可以发现数据中隐藏的规律和模式,从而更好地理解数据背后的故事。
2. 数据可视化:聚类可以帮助我们将复杂的数据可视化,让数据变得更加直观易懂。
3. 决策支持:在商业、医疗、金融等领域,聚类可以帮助我们做出更明智的决策。
4. 异常检测:聚类还可以帮助我们识别出数据中的异常值,从而提高数据质量。
二、聚类的魔法师:常见聚类算法

那么,如何实现聚类呢?这就需要借助一些神奇的魔法师——聚类算法。下面,让我们来认识几位常见的魔法师:
1. K-Means聚类:这位魔法师擅长将数据划分为K个簇,每个簇由一个质心(Centroid)表示。它就像是一个“分蛋糕”的魔法师,将蛋糕切成K块,每块蛋糕代表一个簇。
2. 层次聚类:这位魔法师擅长根据数据点之间的相似性逐层建立层次关系。它就像是一个“建树”的魔法师,将数据点一层层地连接起来,形成一个树状结构。
3. DBSCAN聚类:这位魔法师擅长基于密度的聚类算法,通过点的密度分布发现簇。它就像是一个“找朋友”的魔法师,将密度高的点聚集在一起,形成一个个簇。
三、聚类的魔法表演:应用场景

聚类的魔法不仅神奇,而且实用。下面,让我们来看看聚类的魔法表演在各个领域的精彩表现:
1. 市场细分:通过聚类,我们可以将消费者根据购买行为、偏好等分为不同的群体,以便制定有针对性的营销策略。
2. 图像分割:通过聚类,我们可以将图像划分为多个区域,以便于后续的图像分析和处理。
3. 文本分类:通过聚类,我们可以根据内容将文档自动归类,提高信息检索效率。
4. 异常检测:通过聚类,我们可以识别与众不同的数据点,应用于信用卡欺诈检测、网络入侵检测等领域。
四、聚类的魔法挑战:局限性
当然,聚类的魔法并非万能。在使用聚类时,我们还需要注意以下挑战:
1. 簇数的选择:对于K-Means聚类,我们需要预先指定簇数K,这可能会影响聚类结果。
2. 初始质心的选择:对于K-Means聚类,初始质心的选择可能会影响算法的收敛速度和结果。
3. 数据预处理:聚类算法对数据质量要求较高,需要进行数据预处理,如数据标准化、降维处理等。
4. 评估指标:聚类结果的评估需要选择合适的评估指标,如轮廓系数、Calinski-Harabasz指数等。
聚类就像一位神奇的魔法师,能将杂乱无章的数据变成有序的宝藏。通过了解聚类的魔法原理、常见算法和应用场景,我们可以更好地利用聚类技术,为我们的生活和工作带来更多便利。让我们一起走进聚类的奇妙世界,探索它的无限可能吧!
下载地址



常见问题
- 2025-03-05 梦溪画坊中文版
- 2025-03-05 windows11镜像
- 2025-03-05 暖雪手游修改器
- 2025-03-05 天天动漫免费
装机软件下载排行

其他人正在下载
系统教程排行
主题下载
-
魔笛MAGI 摩尔迦娜XP主题+Win7主题
-

轻音少女 秋山澪XP主题+Win7主题
-

海贼王 乌索普XP主题+Win7主题
-

学园默示录 毒岛冴子XP主题+Win7主题+Win8主题